第一节 爬虫
一、基础知识
爬虫又叫网络爬虫(web Spider),网络像一张大网,上面布满"数据"。
爬虫就是从网上获取数据的"程序蜘蛛"。
步骤:
- 请求网页
- 分析网页
- 展示结果
1、请求网页
爬虫用到的requset库,可以模拟人类打开网页,获取网页的行为。这个过程叫"请求网页"。
requset中的get()方法是进入网站的"法宝"。
request库使用get()来获取网页信息,并输出response对象名和状态码,表示成功获取到了网页。
get("url")函数:get函数用于请求网页,URL是需要请求的网址。
UTF-8:编码格式,避免中文乱码
直接输出get获取的内容,是网页对象名和状态码,其中200是状态码--表示网页请求成功。
代码:
# 爬取网页新闻
import requests
response = requests.get("https://icourse.xesimg.com/programme/static/py/pcdata/lw-web/新闻网站/index.html")
response.encoding = "UTF-8"
print(response)
输出结果:

2、获取网页文本
网页对象.text:获取网页的文本。
格式1:
response = requests.get()
response.text
格式2:
response = requests.get().text
注意text后不加括号
3、分析网页
网页代码是由一个个标签组成的,大多数都成对出现。
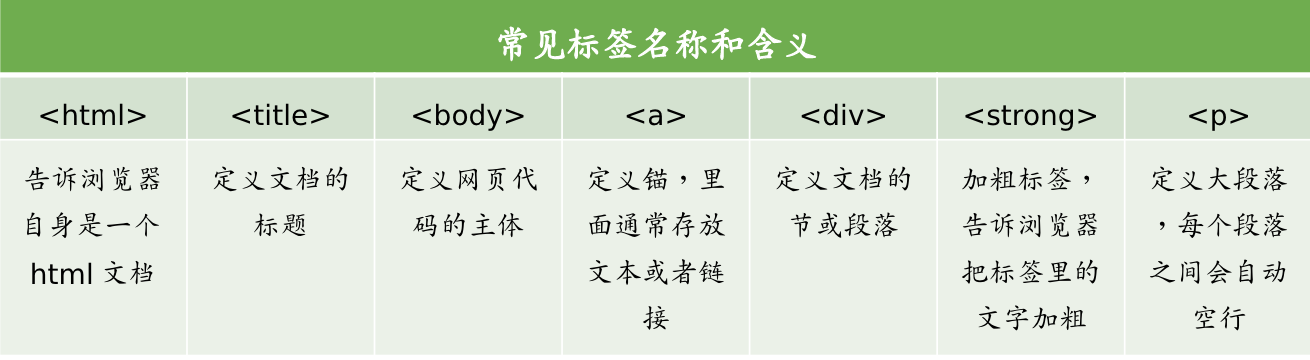
从网页代码中找信息的过程叫做“解析网页”。
4、变为解析对象
bs4库:用来解析爬取的网页,提取信息。
soup是变量名,用来存储解析之后的内容。response.text表示网页文本。lxml表示解析器。
我们可以把创建的对象soup看作是由代码组成的汤。想要提取“汤”中的内容还要借助勺子--“lxml”。
import bs4
soup = bs4.beautifulSoup(response.text,"lxml")
5、获取内容
data保存获取到的内容,是一个列表。
参数name和属性可以根据需要选择使用一个或多个。
常用的属性有id、class_。
data = soup.find_all(name="属性名",属性="属性值")
6、获取标签文字
标签.text方法:获取标签中的文本信息。
格式: data = <标签名>文本信息</标签名> data.text
注意: response.text表示获取字符串格式的网页代码。
这里的data是一对标签,data.text获取标签内容
7、展示结果
代码:
# 爬取网页新闻
import requests, bs4, time
response = requests.get("https://icourse.xesimg.com/programme/static/py/pcdata/lw-web/新闻网站/index.html")
response.encoding = "UTF-8"
soup = bs4.BeautifulSoup(response.text, "lxml")
data1 = soup.find_all(name="div", class_="article")
for n in data1:
data2 = n.find_all(name="a")
print("--------------------------------------")
print("题目:"+data2[0].text)
print("摘要:"+data2[1].text)
print("主题:"+data2[2].text)
运行结果:

8、状态码 response.status_code
response.status_code:用来获取网页当前的状态
response = request.get("url")
response.status_code
| 状态码 | 网页状态 |
|---|---|
| 404 | 找不到网页啦 |
| 200 | 成功找到网页 |
| 403 | 网页禁止访问 |
| 503 | 现在打不开网页,需等待 |
9、文件写入
格式: with open("文件名.文件格式", "写入方式", encoding="utf-8") as file:
file.write(要写入的内容)
要打开文件名需要确定文件路径(文件所在文件夹的地址),或者使用xopen()帮助我们直接找到目标文件
utf-8是编码方式,避免中文乱码
要写入的内容是字符串类型
写入方式:
| 写入方式 | "a" | "w" |
|---|---|---|
| 写入方式的特点 | 在当前文件的末尾添加新的数据 | 清除当前文件内容,重新输入数据 |
with open("新闻.txt", "a", encoding="utf-8") as file:
file.write(要写入的内容)
10、文件读取
格式:with open("文件名.文件格式", "读取方式", encoding="utf-8") as file:
file.read()
"r"表示读取操作
注意read()函数无参数
with open("新闻.txt", "r", encoding="utf-8") as file:
file.read()